Member-only story
SageMaker Pipelines for Efficient Machine Learning Workflows


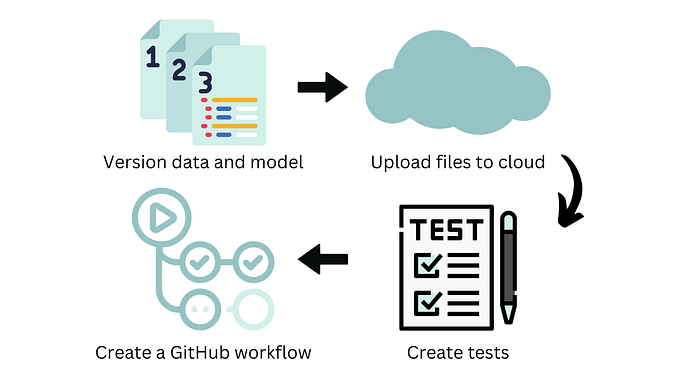
Imagine this: You’re developing a machine learning model to predict customer churn for a large retail company. The datasets are massive, and every time you tweak the model, you need to reprocess and retrain it. Managing this complex workflow with manual scripts quickly becomes overwhelming. This is where SageMaker Pipelines come in handy. With automation and orchestration, SageMaker Pipelines streamline the entire lifecycle of a machine learning model — from data preparation to deployment.
In this article, we’ll explore what SageMaker Pipelines are, how to use them effectively, and why they are essential for anyone working with ML workflows. You’ll also find a sample code to help you build your own pipeline.
What Are SageMaker Pipelines?
SageMaker Pipelines is a feature within AWS SageMaker that allows users to create, manage, and automate machine learning workflows. Think of it as a workflow engine designed to handle the complex stages involved in developing ML models, such as:
- Data preprocessing
- Model training